"Artificial Intelligence attempts to coax a machine, typically a computer, to behave in ways humans judge to be intelligent" John McCarthy (1927-2011)
"I think that there is a lot of fear about robots and artificial intelligence among some people, whereas I'm more afraid of natural stupidity" Eugenia Cheng
Created with Midjourney Bot#9282
Now we can talk with a “machine” using a natural language instead of using programming languages consisting of specific words to be written following a strict syntax and form.
We have a new paradigm in the HCI (Human Computer Interaction) with generative models and large language models.
We can interact with these AI Systems by using “prompt” mechanism, in which we have flexible inputs continued by equally flexible outputs.
In [01] this mechanism is called massive multimodal models.
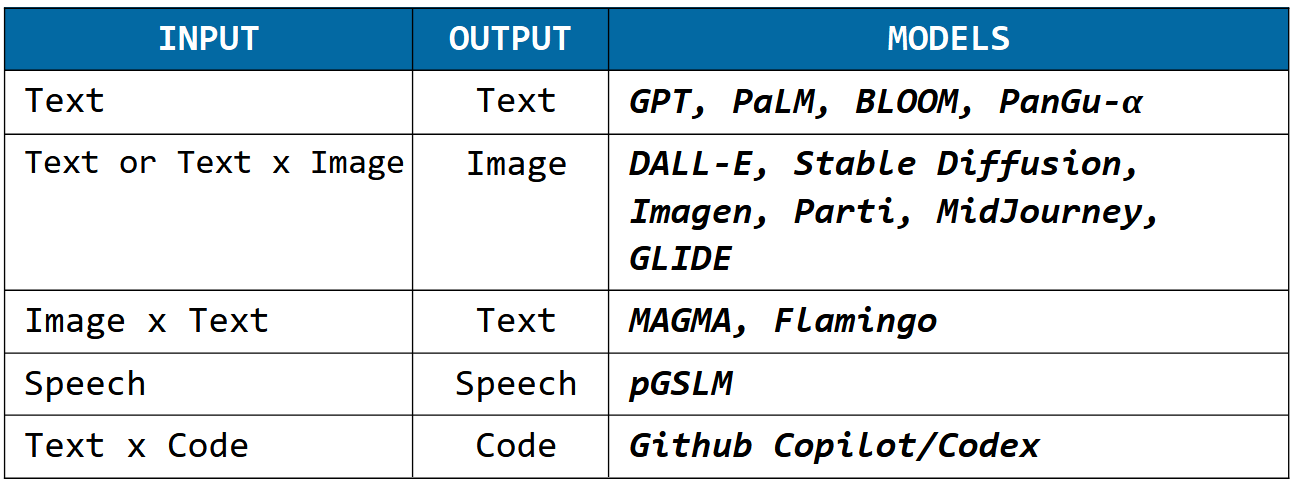
In the following table a selection of different input/output modalities.
"Interaction with prompt-commanded AI is a different from other ways of interaction with machines" [01]. It has three important properties:
flexibility: using of text, code, images etc.;
generality: applicable to broad range of tasks;
originality: generate original content.
"Cognitive tools are external artifacts that are used to aid the psychological capacities of the human brain in completing a cognitive task" [01] They are used to reduce the cognitive work of human brain.
Massive multimodal models are cognitive tools or extenders they can be used for simple o complex interactions. The results depend on the skill and capacity of the user in exploiting these cognitive tools.
AI IMAGE SYNTHESIS: AI Text-to-Art Generator
It is the task where AI learns to understand a description in natural language and reproduce realistic image matching the description. It combines natural language processing (NLP) and computer vision (CV). In this text-to-image tasks NLP model is the encoder and an image synthesis model as the decoder.
Our society is becoming increasingly visual. Images are a very strong means of communication and in this Artificial Intelligence is a very powerful tool.
We can create incredible images (AI Text-to-Art Generator) using AI. Here are some websites where we can create image using AI:
www.bing.com/images/create: AI-powered Bing using its new feature Image Creator: “Powered by the very latest DALL∙E models from our partners at OpenAI, Bing Image Creator allows you to create an image simply by using your own words to describe the picture you want to see. Now users off the waitlist can generate both written and visual content in one place from within chat.”;
openai.com/dall-e-2: DALL·E 2 is an AI system that can create realistic images and art from a description in natural language. It is not free by default.
YOUIMAGINE from you.com: to magically transform your ideas into stunning visuals and one-of-a-kind graphics;
www.canva.com: MagicStudio By Canva allows to supercharge your work and designs with all power of AI.
www.imagine.art : "Create awe-inspiring masterpieces effortlessly and explore the endless possibilities of AI generated art".
davinci.ai : Create AI art using only your words in just a few seconds!
AI-powered Bing’s Image Creator
More specific is the prompt better you obtain the image that you have in mind. Bing’s Image Creator recommends you format your prompts:
Adjective + Noun + Verb + Style.
Small fox running in the forest, digital art
Simple prompt description:
“The centurion in the time of the Roman Empire: the backbone of the Roman army.”
in Bing's Image Creator produce in output:
Complex prompt description
"[...] the centurions must be, not so much men who are bold and contemptuous of danger, as men who are able to command, tenacious and calm, who, moreover, do not move to attack when the situation is uncertain, nor throw themselves into the heat of battle, but on the contrary know how to resist even when pressed and defeated, and are ready to die on the battlefield." POLYBIUS, HISTORIES, VI, 24, 9
Produce:
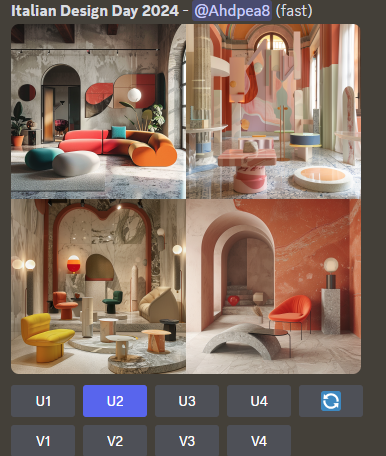
MIDJOURNEY
Let's have a look to midjourney: an AI image generator prompt. A prompt is an input that guides a computer’s AI system in producing an art.
Prompts can range from a simple text description:
“The centurion in the time of the Roman Empire: the backbone of the Roman army.”
that produce:
to more complicated description that involve multiple parts coming together:
"[...] the centurions must be, not so much men who are bold and contemptuous of danger, as men who are able to command, tenacious and calm, who, moreover, do not move to attack when the situation is uncertain, nor throw themselves into the heat of battle, but on the contrary know how to resist even when pressed and defeated, and are ready to die on the battlefield." POLYBIUS, HISTORIES, VI, 24, 9
Produce:
In midjourney the syntax of the prompt in order to generate an image is the following:
/imagine < description text of the image >
What you put in the prompt is very important in order to define the picture that you would have be generated by midjourney.com.
You can ask :
a photo of ...txt...
a painting of ...txt...
you can decide the subject of the photo or painting:
animal;
person;
landscape;
object;
and so on
You can define which details you would like to add:
1) special environment: for example on a boat, in the forest,...
2) special lighting:
soft lighting,
ring lighting,
neon,
and son on
3) colour scheme;
4) point of view:
camera behind;
camera in the front of;
camera beside;
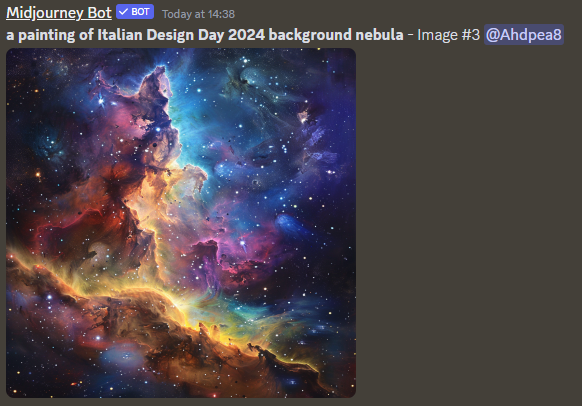
5) background:
solid colour;
a nebula;
a forest;
and so on.
6) atmosphere:
vibrant;
dark;
and so on.
You can add more information, for example the time of the day and so on.
As an image is 1000 words you can ask midjourney.com to generate an image by an uploaded image.
You can merge multiple images into one by using the blending process.
/blend <image1> <image2> ...
You can add additional text to enrich or modify the image.
You can ask also midjourney to get the prompt back (image captioning) using this command syntax:
/describe <image>
This means please describe this image for me.
You can use a negative prompting about you don't really want in the results, putting at the end of your prompt:
--no fog or dust
The you can use other commands:
--aspect 5:4 for aspect ratio
--ar 5:4
--chaos 100 or 90
You can stop the process at a determined percent in order to have an image at different stages.
--stop 50
Human-Computer Interaction but Human-Centred
Massive multimodal models are cognitive extenders and are distinct from autonomous AI systems because they are highly user-dependent.
BIBLIOGRAPHY/WEBOGRAPHY
[01] Wout Schellaert et al., Your Prompt is My Command, Journal of Artificial Intelligence Research, 2023;
[02] Ronald T. Kneusel, How AI works, 2024;
Not generated by AI tools or platforms.
{[(homo scripsit)]}
This website stores cookies on your computer. These cookies are used to provide a more personalized experience and to track your whereabouts around our website in compliance with the European General Data Protection Regulation. If you decide to to opt-out of any future tracking, a cookie will be setup in your browser to remember this choice for one year.